【簡単】Stable Diffusionの使い方(作例あり)【初心者向け】

※当サイトの記事はアフィリエイト広告を利用しております。
こんにちは、モトセ・マヒロです。
突然ですが、冒頭の画像とても綺麗だと思いませんか?実はこれ、これから紹介するStable DiffusionというAIで作成しました。
この記事では
- 今世間で話題になっているStable Diffusionを使ってみたい。
- どんなことができるのか知りたい。
このような疑問にお答えします。
この記事ではこれからStable Diffusionを始めてみたい人向けに解説をします。
記事を読むことで始め方と活用方法について知ることができます。
また、記事後半では私が実際に作成した画像をご紹介します。
※この記事に使用した画像はすべて私がAIで作り出した画像になります。
【ざっくり説明 Stable Diffusionとは】
Stabel Diffusionは2022年8月に公開された画像生成AIのことです。
呪文(以下Promptと記載します)というAIを操作する構文を入力すると、
人がイメージする画像を自動で生成してくれます。
他にもいくつか画像生成AIはありますが、中でもStable Diffusionはオープンソースということもあって、世間で話題になりました。しかも無料。
なにやら難しそうに聞こえますよね。
でも安心してください。始め方は簡単だったので今回は一番始めやすい方法をご紹介します。
まずは結論です。
初心者はGoogle Colab環境でStable Diffusionを始めましょう。

どんなものかちょっと触ってみたいという方にはGoogle Colab環境をお薦めしています。
なぜかというと、
- PCのスペック関係なく使用できるから
- Googleアカウントがあればすぐに始められるから
です。
自分のPCのローカル環境で起動させる方法もありますが、
GPUのスペックがかなり必要で若干難しいので、この記事ではGoogle Colab環境での始め方を解説します。
それでは手順を解説します。
Stable Diffusionを始める手順

手順は次の3つになります。
手順1:Hugging Faceでトークンを取得する
手順2:Google Colabを起動して初期設定をする
手順3:Stable DiffusionをインストールしてPromptで画像を作る
たったこれだけです。
手順1:Hugging Faceでトークンを取得する
まずHugging Faceにアクセスしてアカウントを作成します。
ログイン画面が出るので、Sign Upをクリックし、メールアドレスとパスワードを入力。確認メールがきたらメール内のリンクをクリックして、そのままSing Upします。
Sign Upが完了したら、右上のアカウントのアイコンをクリックして「Settings」をクリック、
「Access Tokens」を取得します。
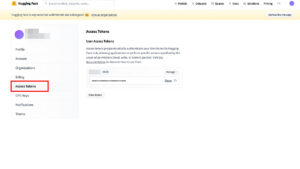
ここで取得した「Access Tokens」はあとの手順3で使うことになります。
ここまでが手順1です。
手順2:Google Colabを起動して初期設定をする
続いてGoogle Colabを起動します。
右上のログイン画面からGoogleアカウントでログインします。
ログインができたら以下の画面が出てくるので、「ノートブックを新規作成」します。
ここからStable Diffusionを始める前の設定をします。
「編集」>「ノートブックの設定」を開きます。
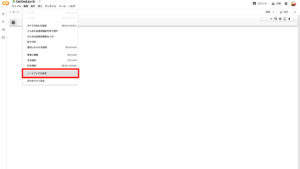
設定画面が出るので、ハードウェアアクセラレータを「GPU」にして保存したら設定完了です。

手順3:Stable DiffusionをインストールしてPromptで画像を作る
Google Colabの設定まで完了したら、実際にStable Diffusionをインストールして動かしてみましょう。
Google Colabでコードを実行するときは左上の「+コード」を押します。
すると、再生ボタンのあるコードセルが出てきます。ここにコードを書いて実行ボタンを押すとGoogle Colabが動いてくれます。(最初は1行分デフォルトで表示されています。)
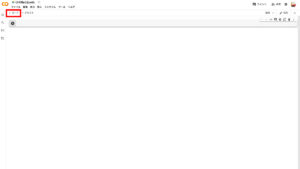
ということでまずはStable Diffusionのインストールです。
以下のソースコードをコードセルに貼り付けして実行します。
!pip install diffusers==0.3.0 transformers scipy ftfy
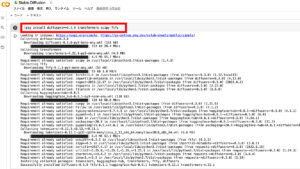
実行すると長いプログラムが実行されるので実行完了するまで待ちましょう。
処理が完了すると再生ボタンの左に緑のチェックが入ります。
続いて「+コード」を押してコードセルを下に追加します。
以下のコードを” ”の中に、手順1で取得した「Access Tokens」を貼り付けて実行します。
YOUR_TOKEN=“ここに自分のAccess Tokenを貼り付けて実行してください”
実行完了したら、さらにコードセルを追加して、以下のコードを貼り付けて実行します。
これでStable Diffusionのインストールが完了です。おつかれさまでした!
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
“CompVis/stable-diffusion-v1-4”,
use_auth_token=YOUR_TOKEN
).to(“cuda”)
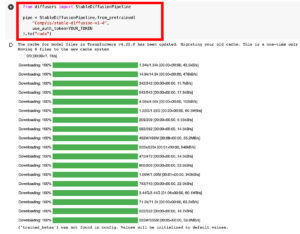
準備ができたので早速Stable Diffusionを動かしてみましょう!
コードセルを追加してPromptを入れて実行します。
基本構文で「椅子の上でくつろぐ可愛い白猫の絵」という条件で画像作成してみました。
↓のpromptを参考に動かしてみてください。
from torch import autocast
# promptの“ ”の中に自分が作りたいイメージ画像のキーワードを入れて実行する
prompt = “an illustration of a white cat on the chair,kawaii,relaxing”
with autocast(“cuda”):
images = pipe(prompt, guidance_scale=10).images
images[0].save(“output.png”)
どんな画像が出てきましたか?私はこんな画像が出てきました。(かわいいw)

※同じ条件でも毎回作られる画像は異なります。
画像は画面左の目次「output.png」ファイルから参照できます。
とりあえず最初は上の基本構文のpromptの中に自分の出力イメージを英語で入れて実行しましょう。
prompt内に複数条件を入れる場合はカンマ(,)で区切りながら入れていきます。
英語の方が精度が高まるそうなので英語推奨です。
このpromptに入れるキーワードを的確にすると生成画像の精度があがります。
いろいろなキーワードを入れて試してみてください。
Stable Diffusionを始め、画像生成AIはこのpromptをいかに使うかが重要になってきます。
今現に「どうやったらイメージ通りの画像を作ることができるか」をエンジニアの方々が研究されてます。プロンプトエンジニアなんて職業も今後出てきそうです。
Stable Diffusionの作例とその呪文(Prompt)

ここからは私がStable Diffusionで作った画像の作例とpromptについてご紹介していきます。
Stable Diffusionはイラストだけでなく、リアルな写真も生成することができます。
私自身いつもはNikonのカメラで写真を撮っているので、その撮影知識を活用して画像を作ってみました。
今回試したこと
- カメラの露出設定をpromptに入れると再現してくれるか?
- ストロボ撮影したポートレート写真が作れるか?
- 「存在しないレンズ」をpromptに入れたらどうなる?
では作例にいってみましょう。
カメラの露出設定をpromptに入れると再現してくれるか?
結論からいうと露出設定を再現できました。
露出をざっくり説明すると明るさのことです。
F値、シャッタースピード、ISO感度の3つで決まります。
実際に promptに入れてみました。レンズの画角は35mm、20mm、600mmの3パターンで出力しています。
【35mmの単焦点レンズで撮影した富士山】
from torch import autocast
#逆光でマジックアワーの富士山を35mmのレンズで撮影した風景写真
prompt = “a photo of Mt.fuji,landscape,magic hour,Nikon AF-S NIKKOR 35mm f/1.8G ED ,f8,1/500 sec shutter,ISO 640,backlight”
with autocast(“cuda”):
images = pipe(prompt, guidance_scale=8).images
images[0].save(“output.png”)
出力された画像はこちら

いや、すごい…。こんなに綺麗に再現されるとは…。
ちなみに撮影設定は「自分が撮るならこんな感じの設定にするかな」という設定にしています。
レンズの製品名をそのまま入れていますが、どの程度レンズの描写が再現されているかは正直分からないです。ただ、画角・構図・色の出し方がとても綺麗ですよね。
【20mmの単焦点レンズで撮影した夜の富士山】
from torch import autocast
#天の川を背景に夜の富士山を撮影した二分割構図の風景写真
prompt = “a photo of Mt.fuji,landscape,2 division composition,starry sky,milky way,AF-S NIKKOR 20mm f/1.8G ED,20mm,f1.8,13 sec shutter,ISO 2000”
with autocast(“cuda”):
images = pipe(prompt, guidance_scale=8).images
images[0].save(“output.png”)
出力された画像はこちら

20mmの超広角レンズを使うなら星空を入れたいと思い、このpromptにしてみました。ちょっと富士山が青すぎるけれど、こちらも綺麗です。
promptに書いていないのにリフレクションまで作ってくれているのもすごいです。
【600mmの単焦点レンズで撮影したカワセミ】
from torch import autocast
#水面にクチバシから飛び込む瞬間のカワセミ
prompt = “a photo of Kingfisher,flying,jump into water surface,from the mouth,sharp angle,a moment,morning glow,AF-S NIKKOR 600mm f/4G ED VR,1/4000 sec shutter,ISO 100”
with autocast(“cuda”):
images = pipe(prompt, guidance_scale=8).images
images[0].save(“output.png”)
出力された画像はこちら

すごいですね!ちゃんと水の写り込みの部分も再現されています。
こういった細かい部分まで再現できると「合成っぽさ」がなくなって自然に見ることができますね。
欲をいうとクチバシが水面に触れるか触れないかくらいで斜めに飛び込む瞬間の画像が作れたらと思いますが、prompt次第でしょうか。
ちなみに自分は超望遠レンズでカワセミを撮影したことがないので、今回の画像を作るにあたってカワセミの撮影設定を調べました。
もし撮影したことがないジャンルの画像を作りたいときは基本的な撮影設定を調べてみるのもいいと思います。
【魚眼レンズで撮影した木】
from torch import autocast
#魚眼レンズで撮影した逆光の樹木の写真
prompt = “a photo of thick tree,landscape,Low – Angle shot,beam of backlight,golden hour,SIGMA 15mm F2.8 EX DG DIAGONAL FISHEYE,f11,1/250 sec shutter,ISO 100”
with autocast(“cuda”):
images = pipe(prompt, guidance_scale=8).images
images[0].save(“output.png”)
出力された画像はこちら

魚眼レンズ特有の「歪み」が再現されるのか知りたくなって作成しました。
レンズの特性も活かしつつ破綻しない画像ができていますね。画像が荒くて少々分かりにくいですが周辺光量落ちも再現されていそうです。
ストロボ撮影したポートレート写真が作れるか?
「風景は綺麗に作れても人物写真とかはちゃんと綺麗に作れるの?」という疑問からこちらも試してみました。
結論からいうと、ポートレート風画像は作れました。ただし、自分がまだpromptを使いこなせていないので「細かいストロボの設定」を反映させることはできませんでした。
雰囲気だけ作れた、という感じです。
from torch import autocast
#金髪のウェディングドレスを着た女性のポートレート写真
prompt = “a photo of beautiful young woman,portrait photography,smilling face,atmospheric,golden medium hair,wearing wedding dress,ニコン AF-S NIKKOR 85mm f/1.4G,f8,1/125 sec shutter,ISO 100”
with autocast(“cuda”):
images = pipe(prompt, guidance_scale=8).images
images[0].save(“output.png”)
出力された画像はこちら

雑誌の表紙にありそうな綺麗なモデルの写真が出てきました。
ここまで様々なタイプの画像を作ってきましたが、「人物画像もしっかり作れてしまう」ことに驚きです。
”レンブラントライト”などの細かいストロボの設定までは再現できませんでしたが、自然光で撮影した感じじゃないことが汲み取れます。
ちなみに人物の画像を試行錯誤して作っていたら、
「NSFW(Not Safe For Work)=職場閲覧注意」のエラーが出ることがありました。
人物モデルを扱う時に着ている服を指定していないとたまに出ることがあるので、あらかじめ「着ている服をpromptで指定」することで回避しました。
次の画像をご覧ください。

あらかじめ「ウェディングドレスを着ている女性ポートレート」とpromptに書くことで、エラーを回避できました。
どんな被写体を写すのか、主題を明確にすることがポイントかもしれません。この辺は写真に通ずるものがありそうです。
「存在しないレンズ」をpromptに入れたらどうなる?
これは自分の純粋な興味です。
上でご紹介した「カワセミの画像」は600mm f4という実在する望遠レンズをpromptに書きました。
そこで「例えば600mm f1.2といった”この世にないレンズ”をpromptに書いたら再現してくれるのだろうか」と思って実験しました。
promptは以下のとおりです。
from torch import autocast
#水面にクチバシから飛び込む瞬間のカワセミ(存在しないレンズで撮影)
prompt = “a photo of Kingfisher,flying,jump into water surface,from the mouth,sharp angle,a moment,morning glow,AF-S NIKKOR 600mm f/1.2G ED VR,1/4000 sec shutter,ISO 100”
with autocast(“cuda”):
images = pipe(prompt, guidance_scale=8).images
images[0].save(“output.png”)
出力された画像はこちらです。

promptで変えたところはF値の部分だけです。
なんなら今まで作ってきた画像の中で一番綺麗だと思ってしまった一枚になりました。一応画像の破綻は起きずに出力されました。
「カワセミの瞳にピントがあっていて、他の羽や背景はf1.2でボケている」といった印象です。(望遠レンズの背景ボケも要素としてはあると思います。)
この出力結果から、レンズの製品名はともかくpromptに書いている焦点距離とF値でAIが判断しているのかな、とも思いました。
以上がフォトグラファー視点で試行錯誤してみた作例になります。
今回は基本的な始め方についてのレクチャーをしました。
普段写真を撮っている身としては今後もStable Diffusionの進化は追い続けたいので、分かったことは随時記事にまとめていきます。
ここまで読んでくださりありがとうございました!
この記事の解説を読んで、「AIもいいけどカメラもやってみたい」と思った方はこちらの記事もどうぞ。初心者向けにカメラの選び方について書いています。
【初心者向け】一眼デジタルカメラの選び方(結論:妥協せず好きなモデルを買う)